みんなの「作ってみた」
【個人開発】Qiitaの人気の記事・ユーザー・書籍を見つけられるWebサービスを作りました
2019/09/17

Qiitaの人気の記事・ユーザー・書籍を探せるWebサービスを作成・公開しました↓↓
「QT Visualizer」
作成の背景
昨年末ごろからなにかしらのWebサービスを作りたいなぁと思っており、よさそうなネタが浮かんではGoogle Keepにメモしていました。
ただ、ネタは浮かんでも実力が追い付いておらず、なかなか着手できない状況のなか、ふと、Web APIを使用したWebサービスであれば比較的難しくなく作れるのでは?(根拠なし)と思い、普段から利用しているQiitaで、Qiitaが提供しているAPIでWebサービスを作ってみようと思ったのがきっかけです。
作った今では全然似てもいないですが、当初はQiitaのAPIを使った、GoogleトレンドのようなWebサービスを作ろうと考えていました。。
実現性の検証
いざWebサービスを作ろうと決心しても、作れるのかどうか確認しないといけません。特に今回のWebサービスは外部サービスが提供するAPIを利用するので、Webサービス構築の技術的なことは置いておいたとして、QiitaのAPIがどこまで使えるのか最初に検証しました。
結果として、Qiitaの投稿取得APIで1投稿の必要十分な情報が取得できることかつ、試しで作ったスクリプトでQiitaの全記事を取得できることがわかったので問題ありませんでした。
ちなみにですが、QiitaのAPIは1Hで1000回のリクエスト制限があるので、全投稿を取得するにはそれ以降のAPIリクエストで投稿日をクエリ条件に付けていくと最古の記事まで取得することができますよー
使用したおもな技術
| フロントエンド | バックエンド・バッチ | インフラ |
|---|---|---|
| Vue.js * | Python * | Heroku * |
| Vuex * | pandas * | MongoDb(Heroku Add-on) * |
| Vuetify * | Flask * | Redis(Heroku Add-on) * |
| Vue-Chart.js * | - | Amazon S3 * |
| - | - | CloudFlare * |
*印が付いているものは初めてさわった技術です。はい、お恥ずかしながらすべて初物です。(普段はJavaとかJavaとかJavaとかさわってます)
Vue.jsを使用したSPAで作成しています。当初はRuby on Railsで作り始めたのですが、作るWebサービスを考えるとバックエンドはフルスタックなものはいらない・むしろデータ加工したAPIを返すだけで良いんじゃ?と思い、一気に方針転換してSPAで作るように変更しました。
バックエンドフレームワークも、Flaskに変更しました。
Flaskは一般にマイクロフレームワークと呼ばれていて、1ファイルで成り立つようなくらいなモノで小さく始められます。
が、Flaskの機能自体は少ないわけではなく、ディレクトリ構成なども特に規定があるわけでもなく、自由なので初心者には結構難しいFWなのかなという感じでした。
(RailsやDjangoのように規約に沿って作れば簡単にできるというものがないので)
実際にディレクトリ構成のベストプラクティスがなんなのかわからずかなり調べました。。
→ flask-vue-spa などは参考になります。
また、バックエンド言語もRubyからPythonに変更しました。個人的にはPythonの可読性の良さが好きです。結果的にですが、pandasなどのデータ分析ライブラリも使うことになって、Pythonに変えて良かったかなと思っています。
そして、上記に挙げた技術とSPA含めてすべて初物でしたのでそこはそれなりに苦労しました。。
とくにフロントエンドまわりは普段の仕事でも触っておらず、全く門外漢だったのでVue.js+SPAについてはまとまった勉強時間を確保して最初に技術知識を詰め込みました。
その他の技術はPython含めて、都度調べつつ実装しつつ、、で進めました。
個人的な意見ですが、プログラミングに関しては、勉強して覚えるのではなく、何かモノを作りつつ、わからないところがあれば都度調べてというほうが学習効率は良いのかなぁと思います!
(まったくの初心者は別)
SPAにして苦労したところ
伝統的なhtmlを返すシステムよりも、単純に工数が上がると思います。
あと、これは私のJSの知識の無さからくることですが、気を抜くとそれなりにメモリリークが発生してしまいました。。都度、メモリのスナップショットを比べて地道に原因を探っていました。
プラスしてエラー周りの処理などSPAならではの実装を考慮しないとなかなか難しいものがありました。
ただ、Vue.jsはすごくとっつきやすかったのでおススメです(公式ドキュメントも充実してます!)
SPAにして良かったところ
優れたUXを提供できます!(というのが一般的に言われているみたいですね)
今回作成したWebサービスではそんなことは思っておらず、個人的にはSPAの技術を学べたのが良かったかなと思っています。
私はSier業界にいるのですが、この業界ではフロントエンドに精通しているエンジニアは少なく、SPAについてわかる人なんてはっきり言って希少です。
そういう特徴があるので、今後のお仕事のためにも今回SPAを選択したというのもあります。
デザイン面について
エンジニアがなにかしら個人開発を行う上で、デザイン面については苦労するのではないでしょうか?
少なくとも私はそうでした。自分自身はエンジニアであって、デザイナーじゃあない。天性のデザインセンスがあるわけじゃないし、今後その道で食っていくわけでもないのでそこに力を入れて学ぶのは得策じゃありませんでした。
なので、UIフレームワークとしてVuetify.jsを導入しました。
UIコンポーネントでVuetifyを全面的に使っており、全体的にVuetifyで統一感を出すようにしています。Vuetifyのおかげで、生cssを書く必要がほとんどなくなっています。
工夫したところ
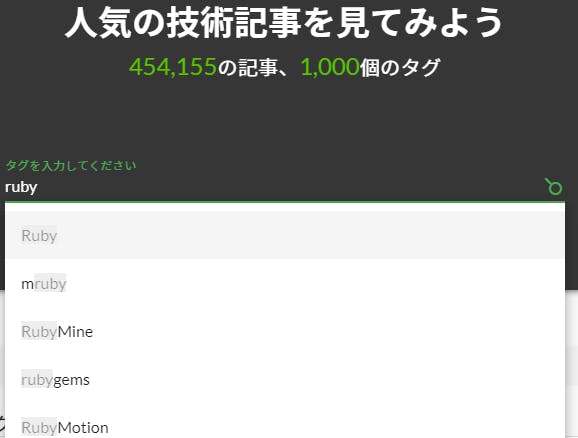
このサービスでは、集計した結果をQiitaのタグで検索することが出来るため、よくある検索ボックスをトップに設けています。
ただ、検索ボックスって何を入れたらよいか迷いませんか?下手に入れて0件データになってしまったり・・・
→このサービスで用意した検索ボックスは入力できる検索語句(タグ)をあらかじめ決めています。かつ、自動補完を利かせているのでそういった問題をなくしています(0件データになってしまうタグは検索不可としています)
制作期間
大体年明けから始めたのですが、始めたころは毎日取り組んでいたわけではありませんでした。また、上記のとおり、フロントエンド周りの勉強を最初にまとめてしていたので、実際の開発は緩めでした。
GW前後から本格的に開発しはじめ、6・7月で一気に作った感じです。
(一番最初にQiitaの全記事取得スクリプトで取得した時の記事数が38万強で、このWebサービスの作成がひと段落着いた時の記事数が43万ぐらいまでのびていました。。)
プロダクション環境での挙動確認の意味もあって、実は8月頭から公開していたのですが、その間は全く宣伝はしていないので実質的な公開はこのQiitaの投稿をもってになるかなと思います。
インフラ周り
herokuにデプロイしています。
無料でどこまでできるか試したかったので、herokuのフリーDynoプランで、カスタムドメインもCloudFlareを使用して、無料で運用しています(add-onも無料枠です)
が、完全に無料ではなく、Amazon S3に月$0.5~2ほどかかっています。
(add-onのMongoDB無料枠がきつそうなので、全然調べていないですがAmazon DocumentDBに移行しようかと考え中…)
サービスのご紹介
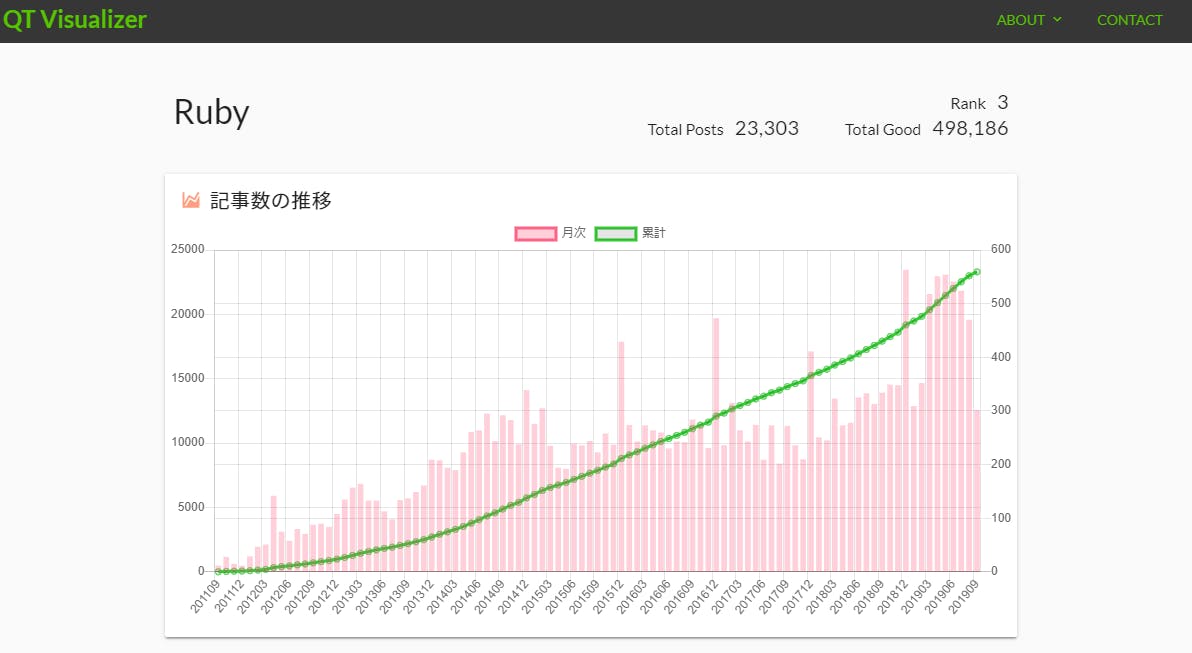
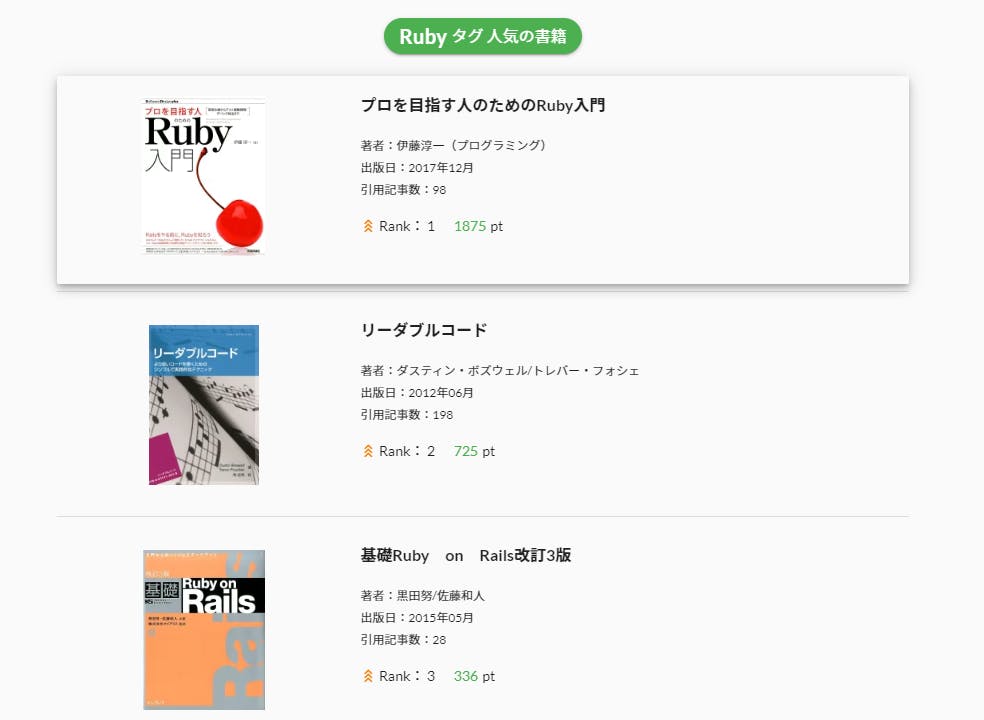
冒頭にも書いたのですが、Qiitaの全記事を取得・分析して人気の記事・ユーザー・書籍を見ることができるサービスです。
分析した結果はQiitaのタグごとに見ることができ、ご自身の興味のある分野(タグ)についての結果を簡単に見ることが出来ます!

さいごに
このサービスを作ってから"ズンドコキヨシ"なる謎のタグがあることを知りました。。。
以上、ぜひ使ってみてください! → QT Visualizer