みんなの「作ってみた」
フロント明るくないおじさんがWebアプリ作った話【悟空語ジェネレーター】
2019/02/08

はじめに
近年、個人開発がとても盛んになってきました。
クラウドサービスのリッチ化に伴い、個人でも簡単にWebサービスを運営できる時代となり、
個人開発者の熱意が更なる個人開発者の熱意を生む、素晴らしい連鎖が発生しています。
特に去年、2018年は爆発的な個人開発ブームでした。
「企業の一兵隊だった自分でも、何者かになれるんじゃないか」
「世界は俺のプルリクを待っているのではないか」
そう思わせてくれる1年でした。
かく言う私も、その熱意にあてられ去年1年間、
ひたすらQiitaを傍観していました。
私の業務はずっとサーバーサイドのJava開発。
フロント明るくないおじさんです。
はじめまして。きんみと申します。以後よろしくお願いします。
作ったもの
とは言え、私も兵隊の端くれ。
血湧き肉躍る開発は大好物なわけでして。
Web開発の真似事のような事はやっていました。年末頃から。
その集大成がこちらになります。
https://goku-lang.netlify.com/
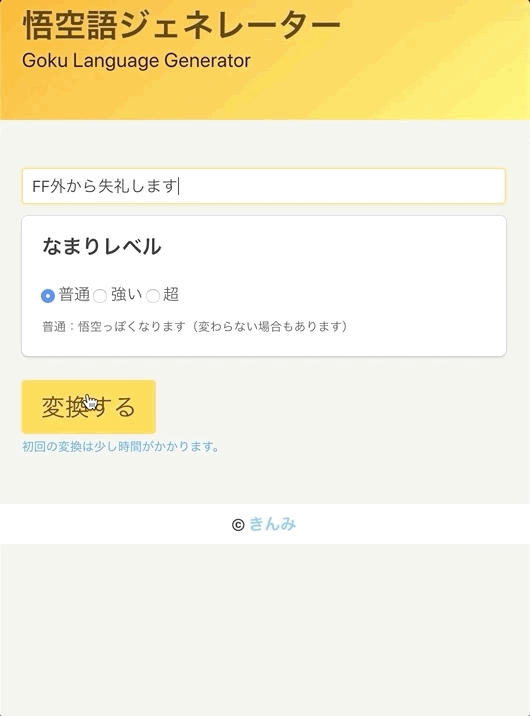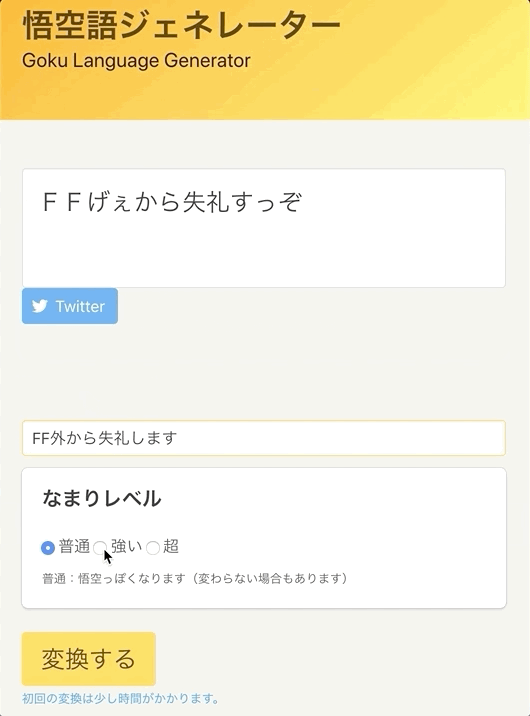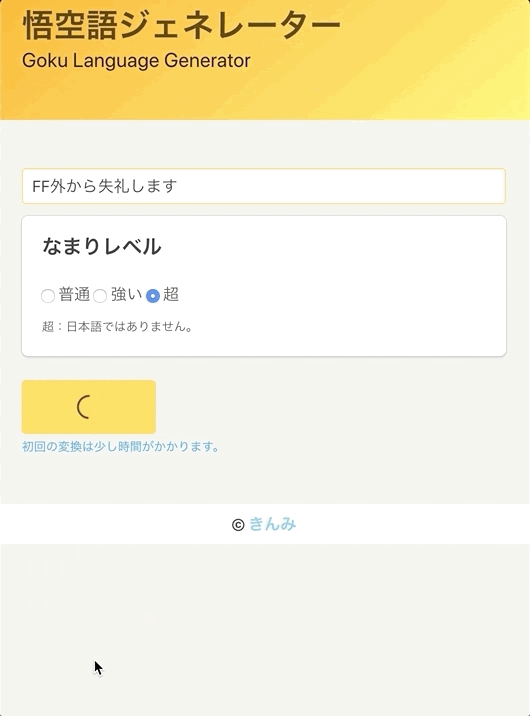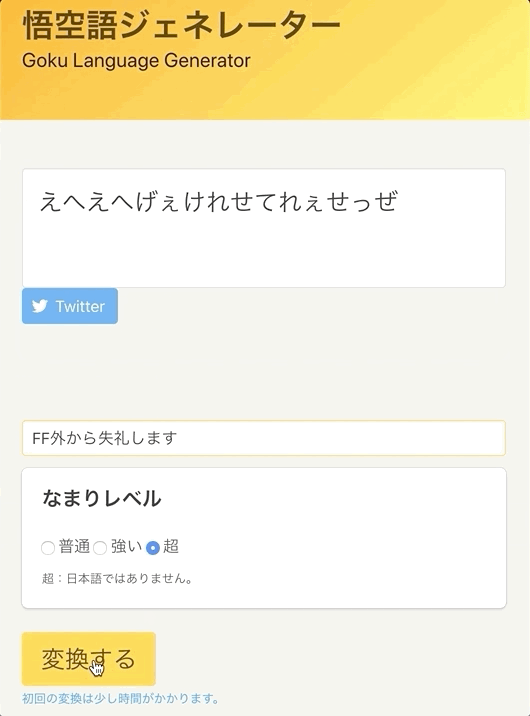
日本語を入力すると、悟空語に変換します。
初回はブラックボックスなサービスとして遊んで頂きたいので、
変換ルールについては最後に書きます。
使った技術
- Vue.js
- JavaScript三大フレームワークの1つ。
- 公式ドキュメントの日本語がとても丁寧で、初学者の私でもとっつきやすいと感じたため使ってます。
- kuromoji.js
- JavaScript製 形態素解析ライブラリ。
- 形態素とは文節の最小単位で、日本語文字列をこの単位で分解して、読み仮名や品詞情報を付与してくれます。
- こちらのデモサイトが分かりやすいです。
- Netlify
- 静的ホスティングサービス。
- ちょー簡単にWEBサイト作れます。
ということで、このサービスは静的なサイトです。
冒頭に話した「リッチなクラウドサービス」は、ほぼ使ってません。
流行りのNetlifyを使ってますが、別にどこだろう動きます。
故・Yahoo!ジオシティーズでも多分動きます。
紆余曲折を経ての結果ですが、ちょっと後悔しています。
後述します。
仕組み
- 入力値をkuromoji.jsで形態素解析
- 各形態素の読み仮名情報をローマ字に変換
- 変換ルールに従い、正規表現でゴリゴリ変換
- 変換された形態素はひらがなへ戻す
- 変換されなかった形態素は元キーワードへ戻す
- 全形態素を文字列結合
たったこれだけです。
ハマったところ
1. フロントゼンゼンワカラナイ
学生時代にHP作った事ありましたし、少しですが業務でjQuery等をイジる事もあります。
しかし、いざ勉強をしてみるとそのカオスっぷりに腰が抜けました。
フロントなんて刺身にたんぽぽ乗せてるだけと思ってた自分を殴りたくなりました。
まずは基本となるHTML5、というより脱TABLEタグから入り、
ES6、Vue.js、React等の公式ドキュメントや入門記事をサーフィンして
Hello Worldな日々を4〜5日程続けました。
広く浅く現代の技術に触れて、無知の知を得る事に徹しました。
2. 形態素解析
React + Kuromoji を使ってブラウザ上で形態素解析
こちらを参考に、Vue.js上でkuromoji.jsを動かせるようにしました。
まずはnpm install kuromojiした後、辞書を公開ディレクトリへコピー。
$ cd project-directory
$ cp -a node_modules/kuromoji/dict public/
下記のようにしてVue.js上でkuromoji.jsを動かしました。
<template>
<div id="app">
<input id="inputText" v-model="inputText">
<button v-on:click="conv">変換</button>
<p>outputToken is: {{ outputToken }}</p>
</div>
</template>
<script>
import kuromoji from "kuromoji"
export default {
name: 'App',
data() {
return {
inputText: "形態素解析される文字列",
outputToken: [],
builder: kuromoji.builder({ dicPath: "/dict" })
}
},
methods: {
conv: async function(event) {
var vm = this
this.builder.build(await function(err, tokenizer){
if(err){
throw err
} else {
var token = tokenizer.tokenize(vm.inputText)
vm.outputToken = token
}
});
}
}
}
</script>
ポイントは下記です。
var vm = this- 通常、単一コンポーネント内ではthisでプロパティを参照するが、
- builder内でも参照できるようにグローバル変数に格納する。
async / await- builder.build は非同期処理の為、async / awaitを使う。
vm.outputToken = token- 形態素解析後のトークンをプロパティへ格納する。
この勘所が全く分からずハマり、Vue.js上でkuromoji.jsを動かす事は一度諦めて、下記を検討しました。
- 代替品としてRakuten MAの使用
- GoogleCloudFunctions(GCF)にkuromoji.jsを置いてAPI化
- GCFにPykakasi(Python製 形態素解析ライブラリ)を置いてAPI化
- MecabをPythonで叩くAPI作成
- 外部APIサービス(Yahoo!JAPAN テキスト解析WebAPI 等)の使用
箇条書きで書きましたがそれぞれ、調査して、コードを書いて、ハマって、諦めてを繰り返してます。
1行につき1〜2日は費やしています。
もっと頑張れば、いずれも実現可能だったかもしれませんが、最終的に「ブラウザ上でkuromoji.jsを実行」に回帰しました。
選定した訳ではなく、現段階の私の技術力ではこれしか出来なかったのです。
3. ローマ字変換
今回の処理は、
入力値をローマ字に変換 → 解析 → ひらがなへ戻す
というフローになります。
便利なJS製のカナ/ローマ字変換ライブラリがいくつかありましたが、
どれもヘボン式で不可逆でした(とうきょう → tokyo → ときょ)
また、解析は正規表現で行うため[sa,shi,su,se,so]のような不規則な変化は避けたく
可逆なローマ字変換処理を自前で作成しました(とうきょう → toukyou)
4. CSSフレームワーク
このアプリはドラゴンボールのネタアプリです。
もちろん、CSSフレームワークはBulma(ブルマ)を使ってます(ドヤ
言いたかっただけです。特にハマってません。
BootstrapからjQuery依存を省いた軽量なCSSフレームワークです。
公式ドキュメントや、下記記事を参考にサクっと導入出来ました。素晴らしい。
CSSフレームワーク BULMA チュートリアル①
マーケティング
フロント技術の学習が目的だった為、開発以外の何かを行うつもりはなかったです。
しかし、せっかくWebアプリを公開するならば、使ってもらえるよう努力したい。
これもまたWebの学習。「やらない」はただの機会損失、と思い
悟空なりきりアカウントをフォローしてみました。
やったぜ!!!
— きんみ (@_kinmi) January 21, 2019
よろしくな!! https://t.co/kVgRtneAMp
今のところ、使って頂いた形跡はありません。
2019/4追記
いつの間にかこちらのなりきりさん、アカウント削除されてました。。
しかし、Twitterで公開したことで、多くのフォロワーさんに使って頂き、バグ報告も多数頂戴しました。
テスト不足が露呈した結果ですが、ローカルで動かしていただけじゃ気付かず終わっていたと思います。
公開して得られる学びの多さを痛感しました。
公開後のバグ対応
① iPhoneでは表示されない問題
Twitterで公開した直後の出来事でした。
見れないです・・・iPhoneだからですかね(´・ω・`)
— 会社やめ太郎(本名) (@jzmstrjp) February 2, 2019
はい、Chromeでしかテストしてません。。。
Safariで開いてみたところ、ブランクページが表示されました。
変換処理で多用していた正規表現の「後読み」が原因でした。
2019/2現在、対応しているブラウザはChromeだけのようです。
ここでJSが落ち、レンダリング自体されない事態に陥ってました。
先読みは使えるとの事だったので下記を参考に、文字列を反転させてマッチさせるという荒技を使いました。
Javascriptでの正規表現の後読みの代替
② ぱい◯いでか美さん対応
ぱいぱいでか美
— 会社やめ太郎(本名) (@jzmstrjp) 2019年2月3日
https://t.co/ESyx59epVx #悟空語ジェネレーター
これは「ぺぇぺぇでか美」にならへんのかいw
想定外です。ワケが分からない。
ぱい系ワードは沢山テストしたのに、何故でか美さんだけ変換されないのか、、、
原因は「ぱいぱいでか」を識別不可なワードとして解析され、
本来カタカナである読み仮名情報がひらがなになっていました。
私の仕様把握不足です。
前提としていた仕様が崩れ、デスマーチが始まります。
やべぇ…
— きんみ (@_kinmi) 2019年2月3日
でか美さん手強い…
原因っぽいの直したら「ぺぇぱいでか美」ってなった、、
どんな処理通ったらこうなるんや… pic.twitter.com/gwF0SffzKS
ぐあぁぁあ!!!
— きんみ (@_kinmi) 2019年2月3日
ちくしょーーーー!!! pic.twitter.com/oLCeRtNyD9
現在は正常に「ぺぇぺぇでか美」となるのでご安心ください。
やらなかった事/やれなかった事
1. バックエンド開発
当初の学習目標は「Firebase Hosting + Cloud Functionsを使ったサーバレス開発」でした。
しかし、結果としてはバックエンド処理の無い、文字通りのサーバレスとなってしまいました。
辞書ファイルをキャッシュするため、初回の変換は超絶重いうえに、挙動のクライアント環境依存が強すぎます。。
友人はスマホの速度制限が来ていたのか、5分かかったと言っていました。
別の友人はAndroid版Edgeなるものを使っていて「動かないよ」と言ってました。
やはり、コアな処理は裏に持たせるべきですね。
また、ユーザが変換したワードの収集が出来ません。
リリース後のメンテナンス作業を見越した場合、生きたデータは貴重です。
こんな小さなネタアプリでも、バックエンド処理は作るべきでした。
2. OGP作成
ここは捨てました。ついでにファビコンもVueデフォルトのままです。
作り出すと拘ってしまい、リリース延期に繋がると思ったからです。
バズを狙う場合は必須ですが、、、
ただ、こちらの記事を拝見して
Vue.jsとFirebaseでOGP画像生成系のサービスを爆速で作ろう
OGPとしてSNSに共有するのは技術的にも面白そうと思ったので、近いうち導入するかもしれません。
モチベーション管理
私のモチベ傾向として、完成までの道筋が見えたら熱が冷めます。
手探りでやっている時が一番楽しいんですよね。
過去にはリリースまで行かず、中途半端に終わったスマホアプリが幾つかあります。
今回も二の舞になるのではないか、という懸念があったので、
完成が見えた段階で@jabbaさん作のmobet を使いました。
週末振休含めて4連休なので٩(๑òωó๑)۶
— きんみ (@_kinmi) 2019年1月23日
今お遊びで作ってる「悟空語ジェネレーター」を公開する。 https://t.co/Nuhjm7PCtp #モベット @_kinmiさんから
しかし、残念ながらこの4連休にインフルエンザにかかるという痛恨のミスを犯してしまい未達成です。
「未達成と判定するまで(期日から判定まで五日間の猶予があります)には完成させる」をモチベーションにリリースまで漕ぎ着けました。
変換ルール
最後に変換ルールです。
当アプリの発想は下記ブログエントリーからです。
野沢雅子語の活用けぇ(活用形)
変換ルールはこちらを肉付けした形になります。
- 1. 母音[a, i] + [i, e] => 母音[e] + 'ぇ'
- e.g.) 最初 → さいしょ → saisyo → selesyo → せぇしょ
- 2. 品詞:動詞 に含まれる 'る' => 'っ' 文末の場合は 'っぞ'
- 文末かつ、動詞+助動詞の場合は後続の助動詞を削除しています。
- kuromoji.jsでは単語の原型(サ行変格活用前、等)のワードも取得でき、そちらもチェックしています。
- e.g.) するから → surukara → sultukara → すっから
- します(する + ます) → suru → sultuzo → すっぞ
- 帰ります(かえる + ます) → kaeru → keleltuzo → けぇっぞ(ルール1と2の併用)
- 3. 一人称 => 「おら」、二人称 => 「おめぇ」
- Wikipediaから一人称と二人称の一覧を作り、固定値で変換かけてます。
- 「貴様」が代名詞として判断されなかったので、「品詞=代名詞」の条件はつけてません。
- ベジータの台詞を悟空語に変換したかったので。
上記がデフォルト挙動であり、なまりレベル:普通です。
なまりレベル:強い/超 は上記に加えて固有の変換ルールが加わります。
- 強い:母音[o] + [i, e] => 母音[e] + 'ぇ'
- e.g.) におい → nioi → niele → にえぇ
- 超:3文字のローマ字(ltu 等)以外の母音全て => 母音[e]
- e.g.) オッス!おら孫悟空!1 → oltusu!orasongokuu! → eltuse!eresengekee! → えっせ!えれせんげけぇ!
なまりレベル:超 は文字だとよく分からないですが、声に出すと意外と読めます。
他のルール発見された方は教えてください!
おわり
次は、すげぇWEBせぇとつくっぞ。
(次は、凄いWEBサイト作る。)2