みんなの「作ってみた」
[個人開発] 英語リーディングをサポートするツールを作った
2019/07/28

AnnoReaderという英語学習者向けのサービスを作りました。
このサービスは、英文にさまざまな付加情報(アノテーションと呼びます)を追加し、複合語の範囲やフレーズの修飾関係などが可視化することで、、英文をより読みやすくします。主に英語の学習者が、日常的な英文リーディングの時に補助ツールとして使うことを想定しています。
この記事は、このサービスの開発のモチベーション実装など技術的な話を紹介します。同じように個人でサービス作りたいと思っている or 作ってる方の参考になればうれしいです。
使い方
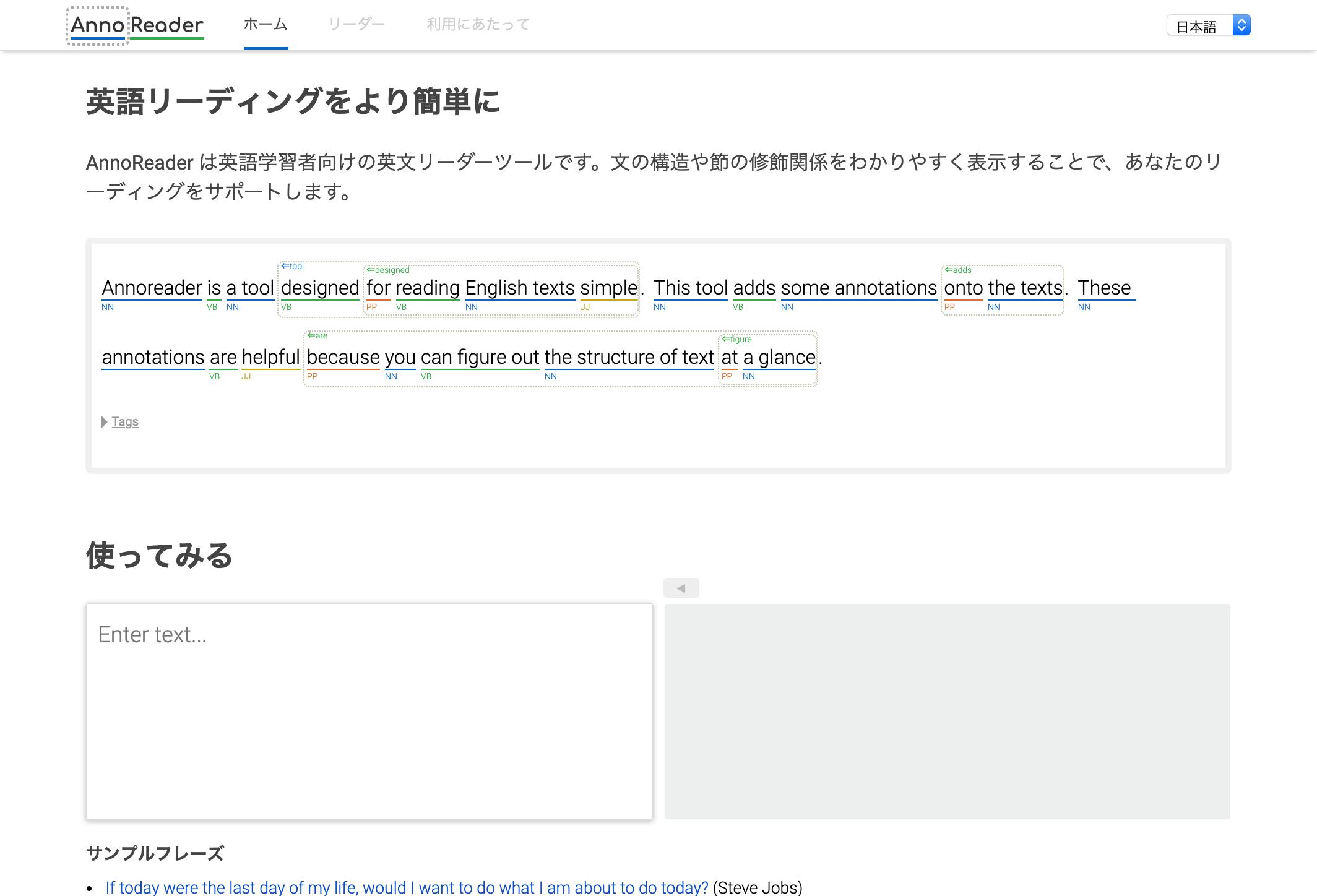
annoreader.comにアクセスして、テキストエリアに英文を入力するだけです。試しに英語を勉強した人なら多くの人が知っている有名な以下のフレーズ
She sells seashells by the seashore. The shells she sells are surely seashells. So if she sells shells on the seashore, I’m sure she sells seashore shells.
これを使ってみると、このようになります

また、Google Chrome と Mozilla Firefoxのブラウザ拡張もあります。日常的に使う場合はこちらの方が便利です。
モチベーションとゴール
エンジニアにとって、英文を読むことは大事なスキルの一つです。Webサイトであったり、論文であったり、README.mdであったり、色々なタイプの英語ドキュメントを読む必要があります。ただ、私も含め英語が苦手な人にとってなかなか大変な作業です。
その中で、私が一つ困ったのが「長文や複雑な文になると理解に時間がかかる or 内容を理解できない」ということです。特に文意を間違えて捉えてそれに気づかないまま読み進めてしまうと、読み終えたときに「あれ?この筆者は何を言っているんだろう?」と疑問だけが残ったりします。そうして翻訳ツールを使ってみると、自分が全く違った理解をしていたことに気づくのです。
このシチュエーションでは、単語を知っていることはもちろん、文の構造を正しく把握することも重要です。どれが主語で、どれが動詞で、どれが目的語なのか、そういった基本的なことはもちろん、節や句の修飾関係も、正しく見つけないといけません。
初見の英文に対してこれらを行うのは、学習者にとって非常に大変な作業です。経験が重要になるからです。AnnoReaderはこの「文の構造の把握」をシステムで解決したかったのです。
以前にMediumに詳細を書いたので、興味がありましたらそちらもご覧ください。
実装
実装面で個人的に面白かったポイントなどを紹介します。
システム概要
AnnoReaderのシステムは、Webサーバーがフロントにあり裏側にAPI的なサーバーを置くような、良くある一般的なWebアプリの構成です。

当初AnnoReaderは、私が自分用に開発したツールでした。なのでリリース後も自宅サーバーの片隅で動かしていましたが、先月くらいからすべてのコンポーネントをコンテナにしてGKE上で稼働させるようになりました。ただ、NLPサーバーはメモリを数GB使うのでクラウド上で動かすと高コストです。なのでこれだけ自宅サーバー上に残しています。各サーバーの役割は後述します。
Webまわり
PHPフレームワークのLaravelを使っています。JSは特にフレームワークは使わずにゴリゴリ書いてます。
Localicationがあるので言語切り替えの実装が楽だったのと、フロントエンド系のツールが統合されているのが非常に便利でした(僕はあまりWebpackの設定とかが得意ではないので)。
また、AnnoReaderのアノテーション表示はすべてHTMLとCSSで実現しています。

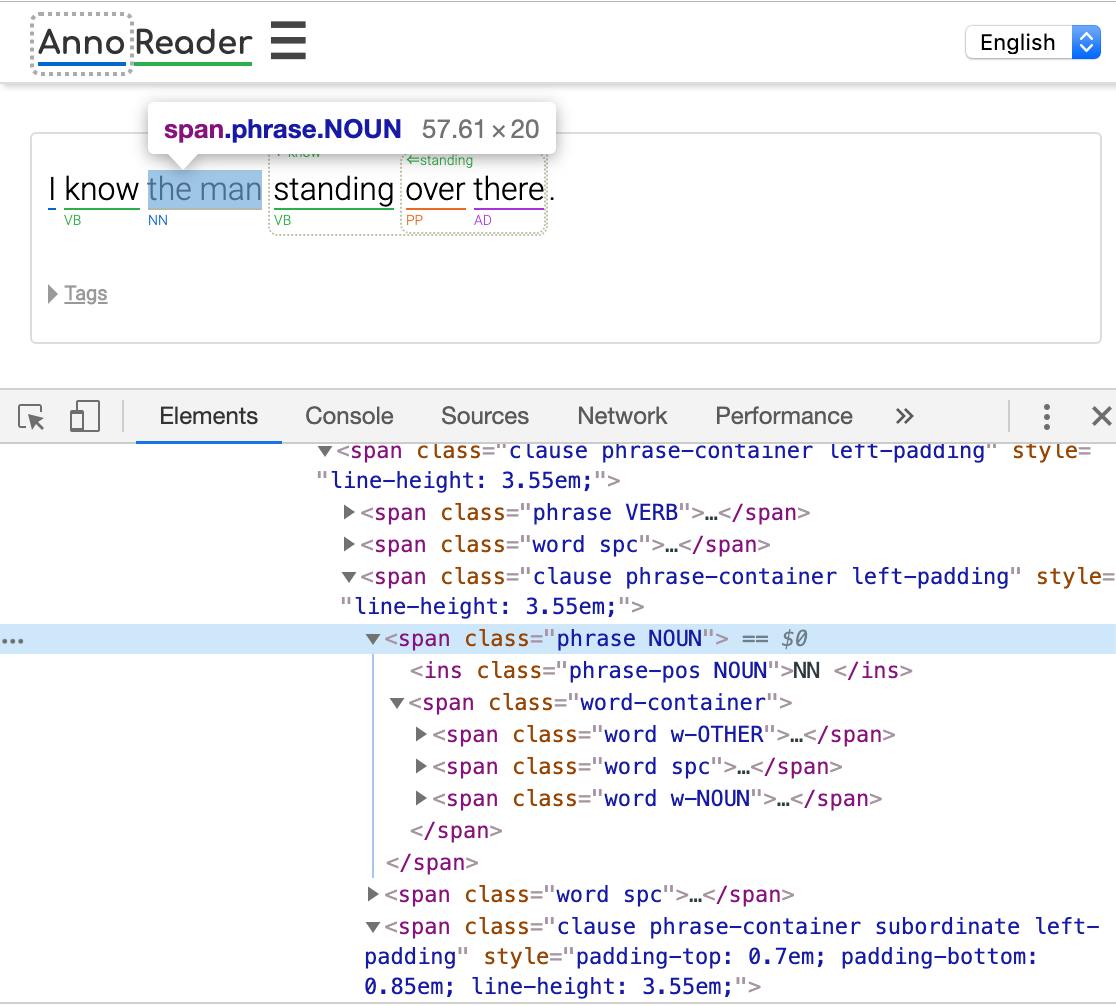
たとえば上記の文でClauseとなる standing over there はこれで一つのSPANタグで、囲っている点線などはCSSの border: 1px dotted $color で表現されています。

ほかにも、"the man"はPhraseになり、これも一つのSPANタグです。CSSで青い下線を表示しています。
HTML+CSSで作ったのにはいくつか理由がありますが、一つ大きなメリットは他のブラウザ拡張がAnnoReader上のテキストにそのまま使えることです。典型的なのはWeblioのようなオンライン辞書です。
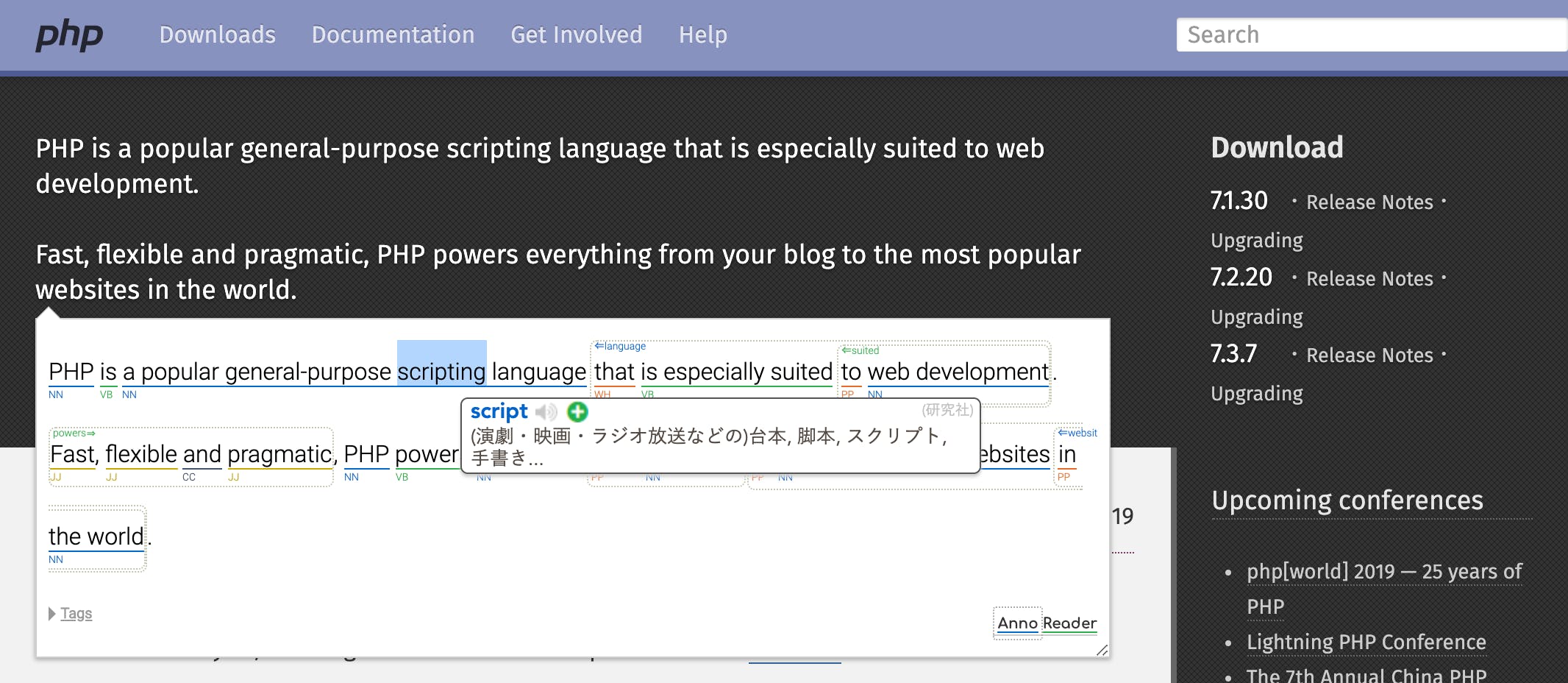
オンライン辞書やGoogle翻訳は、英文を読む人の多くが使っているツールだと思います。AnnoReaderによってアノテーションが付与された英文においても同様のツールが使えるようにすることで、リーディングがより捗るようになります。
英文を構造化する
AnnoReaderは英文の構造を視覚化するわけですから、システム上も英文を単なる文字列では無く構造化して扱う必要があります。現状でAnnoReaderは英文を以下のパートに分解して扱っています。
- Sentence(文) 先頭からピリオドまで
- Clause(節) 複数の語の集まりでS+Vの構造を持つもの
- Phrase(句) 複数の語の集まり
- Word(語) スペースで区切られた一つの単語
そして、Sentenceを最上位、Wordを最下位のオブジェクトとした親子関係を作ります。例えば、
Go is an open source programming language that makes it easy to build simple, reliable, and efficient software. (golang.orgのトップページから引用)
この文章の場合、
- Sencente: 先頭からピリオドまで
- Clause : 「Go is an open source programming language」や「that makes it easy 〜 software」
- Phrase : [an open source programming language」や「efficient software」
- Word : Go, is, an, open, source など
このようになります。
ClauseやPhraseは他のClause, Phrase, Wordを修飾することがあります。例えば上記の文だと that makes it easy to build simple, reliable, and efficient software. というClauseが language というWordを修飾します。
このように構造化された英文情報をJSONで返すAPIを用意しています。エンドポイントは https://anooreader.com/api/annotateです。annoreader.comのWebフォームやブラウザ拡張は裏でこのAPIを利用しています。試しにcurlで直接叩くと、
curl 'https://annoreader.com/api/annotate' -H 'Content-Type: application/x-www-form-urlencoded;charset=UTF-8' --data 'q=Go+is+an+open+source+programming+language+that+makes+it+easy+to+build+simple%2C+reliable%2C+and+efficient+software.'
アノテーションの生成
英文の構造を決定してアノテーションを構築する処理で、AnnoReaderの重要な実装の一つです。先ほどの図で言うと、赤枠の部分です。
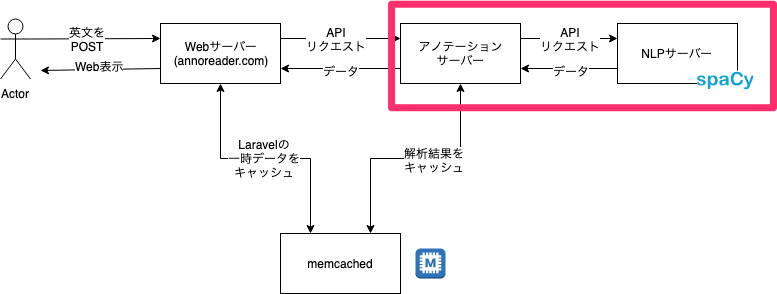
ここではオープンソースのNLPライブラリであるspaCyを利用しています。NLPはNatulal Language Processingの略で自然言語処理と呼ばれています。たとえば単語の品詞(名詞、動詞など)を特定する処理や、単語間の修飾関係(Dependency Parsingといいます)を導いたりする処理があります。Qiitaにも専用タグがあって多くの記事がありますね。
spaCyを使うとどんなことができるのか、以下のサイトでオンライン上で試してみることもできます。実行するとわかりますが、英文に関する非常に多くの情報が取れます。
実際の処理では、アノテーションサーバーがNLPサーバーにテキストを渡して、spaCyのレスポンスを受け取ります。そしてレスポンスを元に、情報の取捨選択、節や単語の修飾関係の整理、複数の単語の統合などを行い、最終的なアウトプットを作ります。
アノテーションサーバーはGoで実装されていて、HTTPサーバーの部分はGinを使っています。
ほかのNLPライブラリ
AnnoReaderは当初spaCyではなくStanford CoreNLPを使って開発していました。これはおそらく一番ポピュラーなNLPライブラリで、ドキュメントや利用事例も多く使いやすかったです。。Java実装ですが、言語バインディングも多くあるので使いやすく、この辺が人気だったりするんでしょうかね。私が書いたGoバインディングもあります。
AnnoReaderの使い方であれば、精度もパフォーマンスもspaCyと並んで十分でした。ただ私がJavaを読めないので、最終的にはPython実装のspaCyを利用するようになりました。
GKE
現状は以下のような使い方をしています。個人サービスでGKEを使うのはtoo muchな印象ですし、実際VPSで十分なのですが、私のKubernetesの勉強を兼ねて使っています。(なのでNode数は1でケチってます...)
# kubectl get secret
NAME TYPE DATA AGE
annoreader-ssl kubernetes.io/tls 2 9d
default-token-tq44z kubernetes.io/service-account-token 3 13d
# kubectl get configmap
NAME DATA AGE
nginx-config 3 13d
# kubectl get deployment
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
annotator 1 1 1 1 9d
memcached-pods 1 1 1 1 13d
web 1 1 1 1 12d
# kubectl get pods
NAME READY STATUS RESTARTS AGE
annotator-bf75679f9-jrwqt 1/1 Running 0 31h
mackerel-agent-rcr4r 1/1 Running 0 37h
memcached-pods-76c6d6dbc8-2jh6b 1/1 Running 0 37h
web-86dc7df9c6-qnf7b 2/2 Running 0 29h
# kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
annoreader-web NodePort 10.0.15.53 <none> 80:32029/TCP 12d
annotator-service ClusterIP 10.0.6.157 <none> 3939/TCP 9d
memcached-service ClusterIP 10.0.1.92 <none> 11211/TCP 13d
# kubectl get ingress
NAME HOSTS ADDRESS PORTS AGE
annoreader-ingress annoreader.com ***.***.***.*** 80, 443 12d
おわりに
個人でのサービス開発は、すべて自分の責任で好きに作れるのでとても楽しいですね。
もしAnnoReaderが皆さんの学習の役に立ったら、開発者としてとてもうれしいです(ぜひフィードバックをください)。
おまけ
Twitterで教えてもらいましたが、こんな不思議な文があるそうです。文法的に正しいですが、これはAnnoReaderでは解析失敗します。面白いですね。
Buffalo buffalo Buffalo buffalo buffalo buffalo Buffalo buffalo.
Buffalo buffalo Buffalo buffalo buffalo buffalo Buffalo buffalo - Wikipedia
さすがにこれは無理でした。ゴメンなさい。
— やへがき やくも〔主〕「カシアス内調」 (@YAHEGAKI_Yakumo) July 7, 2019
Buffalo buffalo Buffalo buffalo buffalo buffalo Buffalo buffalo.
バファロー(地名)のバファロー(野牛。一頭め)がバファローする(脅す)バファローのバファロー(二頭め)はバファローのバファロー(三頭め)を脅す。https://t.co/bhziVnNuDo.